李飞飞创业选择的「空间智能」,完整的 TED 解读视频公布了。

前段时间,路透社独家报道了知名「AI 教母」李飞飞正在创建一家初创公司,并完成了种子轮融资。
在介绍这家初创公司时,一位消息人士引用了李飞飞在温哥华 TED 上的一次演讲,表示她在此次 TED 演讲中介绍了空间智能的概念。
就在今天,李飞飞在 X 上放出了她在温哥华 TED 上的完整演讲视频。
她在 X 上介绍称,「空间智能是人工智能拼图中的关键一环。这是我 2024 年有关从进化到人工智能历程的 TED 演讲,也涉及到我们如何构建空间智能。从看到变为洞察,洞察转变为理解,理解引导为行动。所有这些带来智能。」

李飞飞 TED 演讲链接:
https://www.ted.com/talks/fei_fei_li_with_spatial_intelligence_ai_will_understand_the_real_world/transcript
为了进一步解释「空间智能」这一概念,她展示了一张猫伸出爪子将玻璃杯推向桌子边缘的图片。她表示,在一瞬间,人类大脑可以评估「这个玻璃杯的几何形状,它在三维空间中的位置,它与桌子、猫和所有其他东西的关系」,然后预测会发生什么,并采取行动加以阻止。

她说:「大自然创造了一个以空间智能为动力的观察和行动的良性循环。」她还补充说,她所在的斯坦福大学实验室正在尝试教计算机「如何在三维世界中行动」,例如,使用大型语言模型让一个机械臂根据口头指令执行开门、做三明治等任务。
以下为李飞飞在 2024TED 的演讲实录:
我先给大家展示一下,这是 5.4 亿年前的世界,充满了纯粹而无尽的黑暗。这种黑暗并非因为缺乏光源,而是因为缺少观察的眼睛。尽管阳光穿透了海洋表面,深入到 1000 米之下,来自海底热液喷口的光线照亮了充满生命力的海底,但在这些古老水域中,找不到一只眼睛,没有视网膜,没有角膜,没有晶状体。因此,所有的光线,所有的生命体都是不可视的。

曾经有一个时代,「看见」这个概念本身并不存在,直到三叶虫的出现,它们是第一批能够感知光线的生物,标志着一个全新世界的开始。它们首次意识到,除了自己,还有更广阔的世界存在。
这种视觉能力可能催生了寒武纪大爆发,让大量动物物种开始在化石记录中留下痕迹。从被动地感受光线,到主动地用视觉去理解世界,生物的神经系统开始进化,视觉转化为洞察力,进而引导行动,最终产生了智能。
如今,我们不再满足于自然界赋予的视觉智能,而是渴望创造能像我们一样,甚至更智能地「看」的机器。
九年前,我在这个舞台上介绍了计算机视觉领域的早期进展,这是人工智能的一个子领域。那时,神经网络算法、图形处理器(GPU)和大数据首次结合,共同开启了现代人工智能的新纪元。例如我的实验室花费数年整理的含有 1500 万张图像的数据集,即 ImageNet 数据集。我们的进步非常迅速,从最初的图像标注到现在,算法的速度和准确性都有了显著提升。我们甚至开发了能够识别图像中的对象并预测它们之间关系的算法。这些工作是由我的学生和合作者完成的。
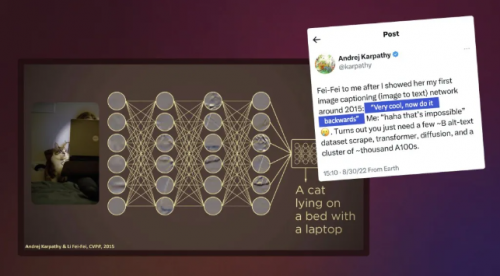
回想上一次我向大家展示了第一个能够用人类自然语言描述照片的计算机视觉算法。那是我与我的学生 Andrej Karpathy 共同完成的工作。那时,我碰运气说,「Andrej,我们能造出反向的计算机吗?」Andrej 说:「哈哈,这是不可能的。」正如你从这篇帖子中看到的,最近这个不可能已经变成了可能。这都要归功于一系列扩散模型,这些模型为今天的生成性人工智能算法提供了动力,该算法可以将人类提示的句子转化为全新的照片和视频。
许多人已经目睹了由 OpenAI 的 Sora 所创造的令人赞叹的视频作品。然而,即便没有大量的 GPU 资源,我的学生和我们的合作者还是在 Sora 之前几个月,成功开发出了一个名为 Walt 的生成式视频模型。

尽管如此,我们仍在不断探索和改进。我们注意到生成的视频中仍有一些不完美的地方,比如猫的眼睛以及它穿过波浪而不被淋湿的细节处理。但正如过去的经历告诉我们的,我们会从这些错误中学习,不断进步,创造一个我们梦想中的未来。在那个未来,我们希望人工智能能够为我们做更多的事情,或者帮助我们做得更好。
多年来我一直强调,拍照和真正地「看」并理解是两回事。今天,我想补充一点。仅仅看见是不够的。真正的「看」是为了行动和学习。当在三维空间和时间中采取行动时,我们将通过观察来学习如何做得更好。自然界通过「空间智能」创造了一个良性循环,将视觉和行动联系起来。
为了说明空间智能是如何工作的,看看这张照片。如果你突然有种冲动想要做点什么,那说明你的大脑已经在瞬间分析了这个玻璃杯的几何形状、它在空间中的位置,以及它与周围物体的关系。这种想要行动的冲动是所有具有空间智能的生物的本能,它将感知和行动紧密相连。

如果我们想让人工智能超越现有的能力,我们不仅需要它能看会说,更需要它能行动。在这方面,我们已经取得了令人兴奋的进展。最新的空间智能里程碑是教会计算机看、学习、行动,并且不断学习如何更好地看和行动,这并不容易,因为自然界花了数百万年才进化出依赖眼睛接收光线、将二维图像转化为三维信息的空间智能。
直到最近,一组来自谷歌的研究人员才开发出一种算法,将一组照片转化为三维空间,就像我们在这里展示的例子一样。我的学生和我们的合作者更进一步,创建了一个算法,它只输入一张图像,就可以将其转化为三维形状。这里有更多的例子。
回想一下,我们曾谈论过一种计算机程序,可以将人类的语言描述转化为视频。密歇根大学的一组研究人员找到一种方法,将一句话转化为三维房间布局。我和斯坦福的同事以及我们的学生开发了一个算法,只输入一张图像,就创造出无限多个可能的空间,供观众探索。
这些都是我们在空间智能领域取得的令人激动的进展,也预示着我们未来世界的可能性。届时,人类可以将整个世界转化为数字形式,这个数字世界能够模拟出现实世界的丰富性和细微之处。

随着空间智能的进步加速,这个良性循环的新时代正在我们眼前展开。这种来回的互动正在催化机器人学习,这是任何需要理解和与三维世界互动的具身智能系统的关键组成部分。
十年前,我的实验室开发的 ImageNet 启用了一个包含数百万张高质量照片的数据库,用以训练计算机视觉。今天,我们正在收集行为和动作的行为「ImageNet」,来训练计算机和机器人如何在三维世界中行动。但这次收集的不是静态图像,而是在建构由三维空间模型驱动的模拟环境。这样,计算机就可以有无限多的可能性来学习如何行动。
我们还在机器人语言智能方面取得了令人兴奋的进展。使用基于大型语言模型的输入,我的学生和合作者们成为了第一批做出了根据口头指令能够让机械臂执行各种任务的团队,比如它可以打开某个抽屉或拔掉手机的充电线,或者它可以制作三明治,加了面包、生菜、番茄,甚至还能为你放上一张餐巾纸。通常我对三明治的要求可能要高于机械臂做的,但这是个不错的开始。
在我们的远古时代,在那片原始海洋中,观察和感知周围环境的能力,开启了寒武纪时期生物物种的大爆发。今天,这道光正在触及「数字形式的生命」,空间智能让机器不仅能彼此互动,还能与人类或者与真实或虚拟形态的三维世界互动,随着这个未来逐渐成形,它将对许多人的生活产生深远影响。
让我们以医疗保健为例,在过去的十年里,我的实验室已经迈出了第一步,探索如何应用人工智能来影响患者治疗的效果以及如何应对医务人员疲劳的挑战。
我们与斯坦福医学院以及其他医院的合作者正在试用智能传感器。它能够检测到临床医生在没有正确洗手的情况下进入病房,并跟踪手术器械,或者在患者面临风险时,如跌倒时,提醒护理团队。这些技术是一种环境智能,就像多了一双眼睛,确实能为世界带来改变。我更希望为我们的患者、临床医生和护理人员提供更多交互式的帮助,他们迫切需要额外的一双手。想象一下,一个自主机器人可以在护理人员专注于病人的时候运送医疗用品,或者在增强现实中,引导外科医生进行更安全、更快、更少侵入式的操作。
或者想象一下这种场景,严重瘫痪的患者可以用他们的思想控制机器人。没错,用脑电波来完成你和我视为理所当然的日常任务。你可以从我的实验室最近的这项实验中窥见这种未来的可能性。在这个视频中,机械臂正在烹饪一份日本寿喜锅,它完全是由大脑电信号控制的,这些信号通过 EEG 脑电帽无创收集。
大约五亿年前,视觉的出现颠覆了黑暗的世界,它引发了最深刻的进化过程:动物世界中智力的发展。过去十年间,人工智能的惊人进展同样令人惊叹。但我相信,直到我们用空间智能驱动的计算机和机器人,这场数字寒武纪大爆发的全部潜力才会完全实现,就像大自然曾对人类做过的那样。
这将是一个激动人心的时刻,我们的数字伴侣将学会推理,并与人类世界这个美丽的三维空间互动,同时也创造更多我们可以探索的新世界。实现这一未来并非易事。它需要深思熟虑,始终以人为本开发技术。但如果我们处理得好,由空间智能驱动的计算机和机器人不仅会成为有用的工具,还将成为值得信赖的伙伴,提升人类生产力,促进人类和谐共处。同时,我们个人的尊严也将更加凸显,引领着人类社会的共同繁荣。
最让我对未来感到兴奋的是,AI 将变得更加敏锐、更加富有洞察力,并具有空间意识。它们将与人类同行,不断追求用更好的方式,来创造更美好的世界。